Extraction online learning
Use extraction online learning to improve the results for documents with unsatisfactory recognition results. During Validation or Thin Client Validation, the user marks these documents for online learning. After validation, the marked documents are then copied to the online learning directory. Extraction online learning is available only for trainable locators.
Marking a document for extraction online learning enables you to and use the Knowledge Base Learning Server module to increase the recognition of documents with the same layout during production. To use this feature, you need geometric information for the document fields. This type of extraction online learning does not require a project to be manually trained and is ideal for projects that process invoices.
This type of learning is designed to optimize field recognition rate during production. This enables faster initial project setup and continuous optimization during production. It is mainly based on the specific training algorithm of all trainable locators and the auto completion option of the Validation module. In order to use this type of online learning, the Knowledge Base Learning Server must be included in the Kofax Capture batch class queue.
Depending on how your project is configured, documents can be marked for extraction online learning in one of 3 ways:
-
Enable Validation or Thin Client Validation users to manually mark documents for extraction online learning
-
Write a script to mark relevant documents for extraction online learning
-
Enable relevant documents to be flagged automatically for extraction online learning
During production, any marked documents are processed by the Knowledge Base Learning Server and then fed back into the project. You can see these documents in Project Builder. The marked documents are displayed in the New Samples document set in the "Extraction" document subset. These documents are processed and then fed back into the Extraction Set to improve subsequent classification and extraction.
When extraction online learning is performed for a document, the following sequence is used to locate field data:
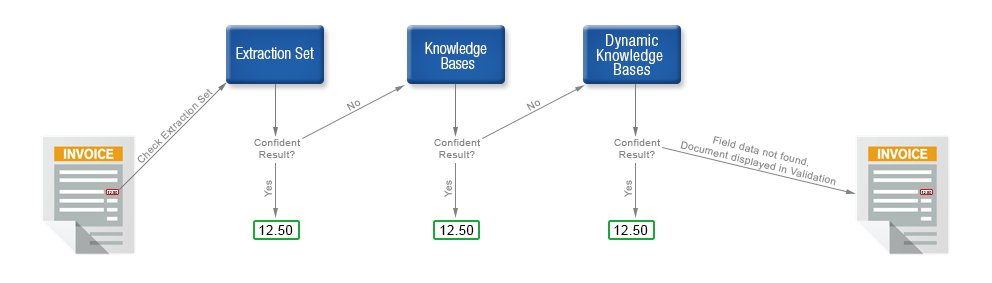
-
First, the Extraction Training Set is used to help with extraction results. If a confident result is found, it is used. If not, processing moves on to the second step.
-
Second, if there are any knowledge bases added directly to a trainable locators (*.kbi, *.kba, *.kbo, *.kbtgl, and *.kbtbl), these are processed. If a confident result if found, it is used. If not, processing moves on to the third step.
-
Third, the Dynamic Specific Knowledge Base is used. If a confident result is found, it is used. This is the last step, so if no confident result is found, the corresponding document will be presented to a Validation or Thin Client Validation user. Depending on how your project is configured, this document may be marked automatically or added manually by the Validation or Thin Client Validation user.
Since the first step is to look in the Extraction Training Set, it is important to keep this training set up-to-date. This means regularly processing your New Samples and training your project when it is first put into production.
If you add the Knowledge Base Learning Server to the workflow queue for the batch class, extraction online learning is available for a batch class. Adding this module to the workflow eliminates the need to manually train your project if you are using Extraction Online Learning.