Extraction benchmarks
In order to optimize your extraction settings, you need to know how accurately your current extraction settings perform when applied to a set of documents. You can test your extraction settings against a set of documents by running an extraction benchmark.
Ideally, this document set should contain documents whose classification and extraction results are always correct. These ideal documents are referred to as golden files.
Running an extraction benchmark processes these golden files using the project extraction settings and compares the extraction results against the stored golden file values.
Selecting a field column in the Summary table loads all documents with that field into the Selection document set.
There are three different extraction benchmark scenarios you can generate. Each open in the Extraction Benchmark window:
- Selected Class Only
-
When this option is selected, extraction using your current extraction settings for the selected class is run against the selected document set in the Documents window. The extraction results are compared to the results in the golden files. Since no classification is run for this option, if one or more of the documents in the test document are not of the selected class, their extraction results are blank in the Extraction Benchmark window.
- Selected Class and its Child Classes
-
When this option is selected, classification and then extraction using your current extraction settings for the selected class and child classes is run against the selected document set in the Documents window. If a document is not classified as the selected class or one of its child classes, it is not included in the Summary or Details table in the Extraction Benchmark window.
- All Classes
-
When this option is selected, classification and then extraction using your current extraction settings for the project is run against the selected document set in the Documents window. The results are displayed in the Summary and Details table on the Extraction Benchmark window.
Once a value is extracted when the benchmark is processed, the comparison between the extracted value and the stored value can result in the following:
- Correct valid fields
-
This result occurs if the currently extracted field value and the stored value are equal. It is not shown to the user in Validation as it has a valid field status and does not require manual validation. Fields with this status are highlighted in green.
This was formerly known as the OK result.
- Correct invalid fields
-
This result occurs if the currently extracted value and the stored value are equal but the field status is invalid. For example, a failed validation rule caused the result to be invalid, or the minimum confidence extraction threshold was not met. A field with this result in a production batch needs to be manually validated by a user. Fields with this status are highlighted in blue.
This result was formerly part of the Reject result.
- Incorrect invalid fields
-
This result occurs because the currently extracted value and the stored value are not equal and the field status is invalid. For example, a field has no extraction result but there is a stored result, or the extracted result differs from the stored result in some other way. A field with this result in a production batch needs to be manually validated by a user. Fields with this status are highlighted in yellow.
This result was formerly part of the Reject result.
- Incorrect valid fields
-
This result occurs if the currently extracted value and the stored value are not equal but the field status is valid. This result is known as a false positive because it is mistakenly marked valid. It is not shown to the user in Validation as it has a valid field status and does not require manual validation. Fields with this status are highlighted in red. Any results with this status need to be addressed before the project is put into production so invalid data is not overlooked.
This result was formerly known as the Error result.
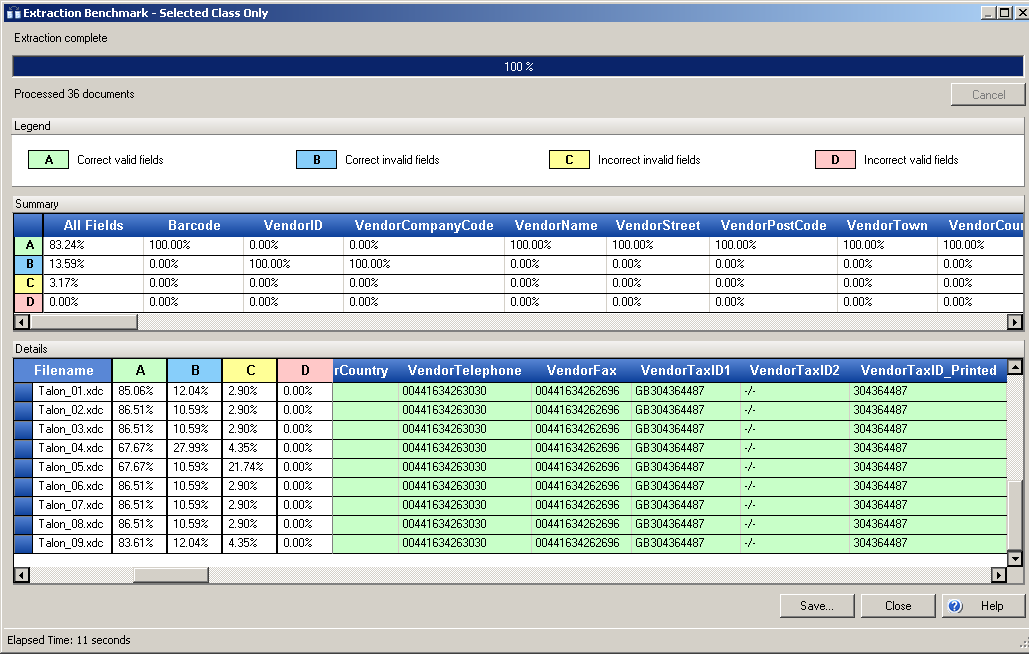
This example shows an extraction benchmark of an invoice class for the supplier Talon. As you can see from the first image, the VendorTaxID_Printed field is marked invalid (highlighted blue), even though this value is exactly what is on the document. This is because the regular expression used for the printed Tax ID expects a two-letter country code, and the field does not match the required validation method.
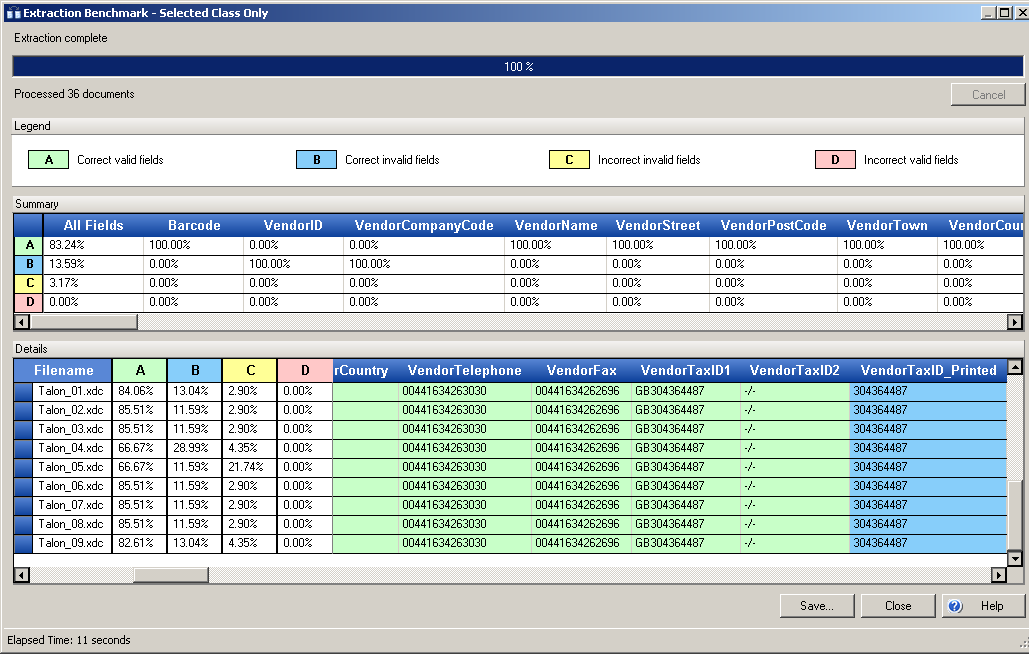
To improve these results, the regular expression was modified to make the two-letter country code optional. The following image shows the new benchmark results.