テーブル構造の不規則性の処理
テーブル行では、含まれるセルの数が異なる場合があります。こうした不規則性に対処する一般的な方法は、各テーブル行の書式をテストすることです。たとえば、特定の数のセルが含まれる行または特定のテキストが含まれる行のみを考慮することが必要な場合があります。
- 各タグ繰り返しステップに、[トライ] ステップを続けます。
-
テーブル行をループするようにトライ ステップを設定します。
トライ ステップの各分岐で 1 つの書式を処理します。この処理は、たとえば、パターンとして記述されたある書式に一致するすべての行を受け入れるタグ判定アクションなど、[次の代替手段を試行] エラー処理による条件ステップで各分岐を開始することによって実行されます。
-
条件ステップに、条件アクションで受け入れられる書式を想定している 1 つ以上の抽出ステップを続けます。
場合によっては、条件ステップと抽出を組み合わせることにより、書式の抽出を試行し、失敗した場合は次の抽出を実行するように設定することができます。
次のロボットは両方のアプローチを使用しています。
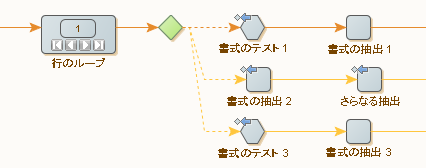
2 番目の書式の抽出は 2 ステップ プロセスであることに注意してください。[次の代替手段を試行] エラー処理は両方のステップに設定されているため、2 つのステップのいずれかが失敗すると、3 番目の分岐が試行されます。これは、2 番目の分岐のかなり複雑な条件を表しています。
このロボットが実行されると、各分岐が、いずれかの分岐が成功するまで順番に実行されます。すなわち、後の分岐の条件では、前の分岐から条件を繰り返す必要がありません。失敗したことが明らかであるためです。
注 条件ステップの後で分岐をする必要はありません。2 つ以上の分岐が抽出ステップを共有している場合、それぞれ異なるステップの後にある分岐は結合することをお勧めします。