Workflow XML Designer
The Workflow XML Designer (manifested by WorkflowXMLDesigner.exe ) is the tool where engineers can create and test workflows for CSDK IWR engine. IWR workflows can be saved into WorkflowXML files. Input and output file names can be templated.
The main screen of the Designer with a simple (OmniPage 123 like) workflow is displayed below. The actual workflow is on the left side. The predefined and custom job items are located on the right. (The application can replace the $inputfile1$ string to the actual full path).
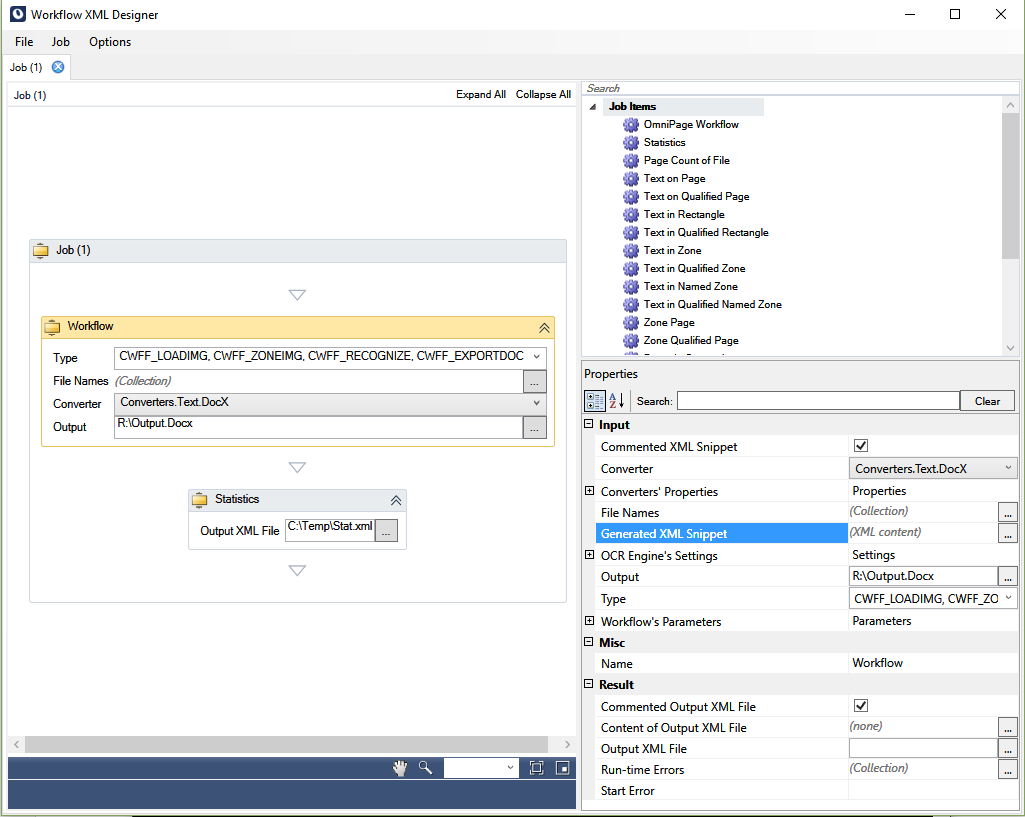
You can test the workflow by selecting .
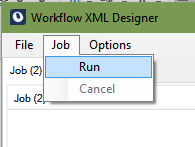
To extend the available output document formats, select .
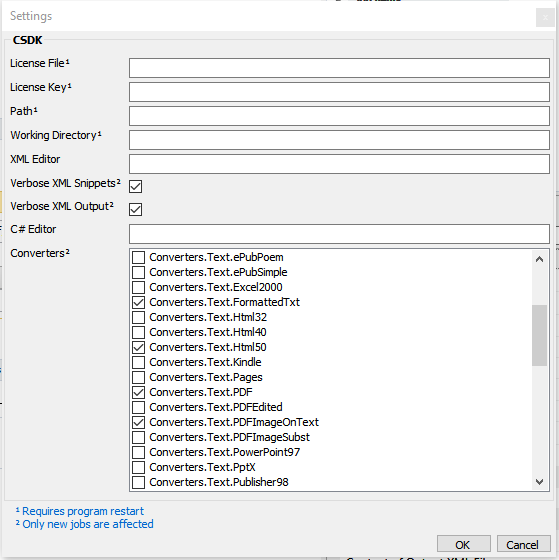
You can set or change all CSDK settings and workflow parameters in the job item Properties window.
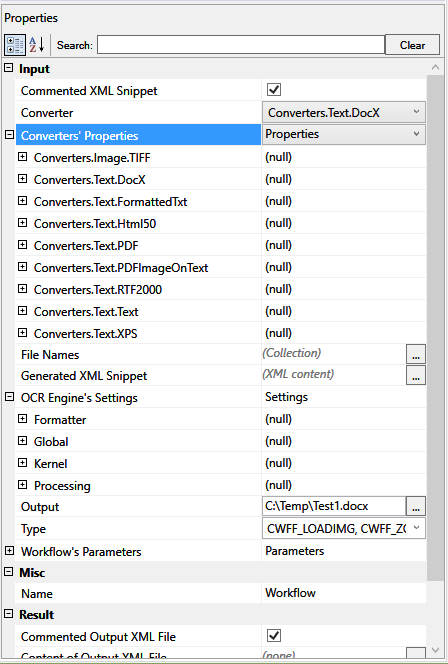
Select the setting and enter the value in the right column.
If you are ready with your workflow, you can save it for later editing, or export it into WorkflowXML file.
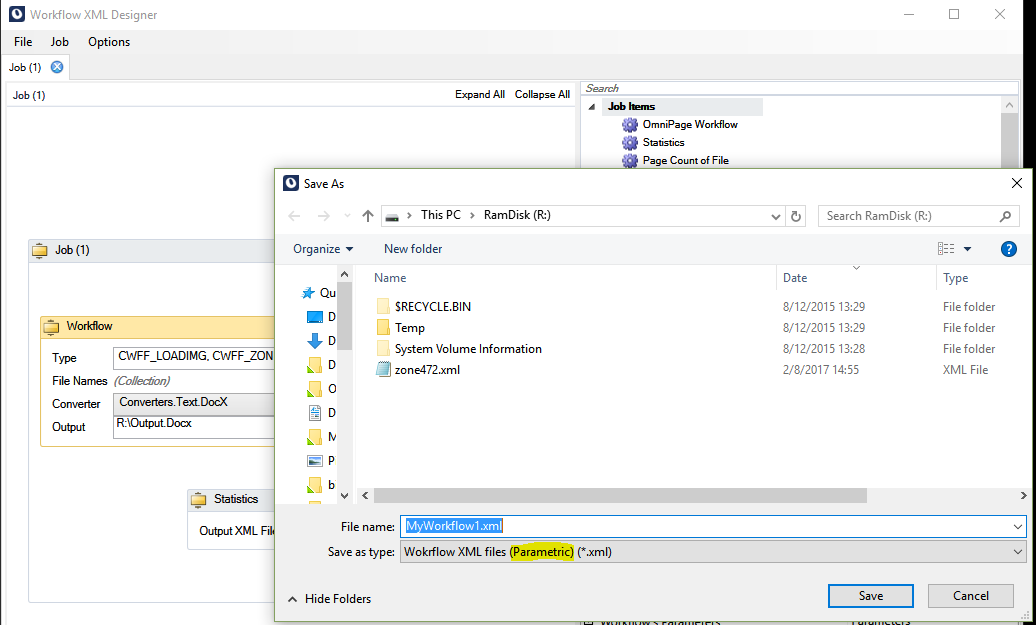
This is the WorkflowXML file (templated version) of a simple workflow.
<?xml version="1.0" encoding="utf-8"?>
<!--This xml will be sent to OCRService.-->
<!--The xml is case sensitive.-->
<!--"type" attibutes determine the interpretation of "value" attributes.-->
<!--If "type" is an exported enum, then symbolic values can be applied.-->
<OCRJob>
<!--clsid: identifies "Workflow" job item type.-->
<!--id: the runtime identifier of this job item instance.-->
<!--This job item will be started immediately.-->
<!--"Workflow" job item executes a standard OmniPage workflow.-->
<!--The number of the available steps is limited.-->
<JobItem clsid="{14ABDDC9-0DF7-4D1C-9687-0AE5F2AD1C3D}" id="{fb1e57a3-7c6f-4bca-88b3-b2b979db116e}">
<!--Definition of the steps in the workflow.-->
<Type type="integer" value="IWFT_WFS_DIRECT|CWFF_LOADIMG| CWFF_ZONEIMG| CWFF_RECOGNIZE| CWFF_EXPORTDOC" />
<!--Definition of the input files.-->
<!--Input files are always passed in an array.-->
<Inputs type="array">
<Input type="string" value="$inputfile1$" />
</Inputs>
<!--Definition of the Document's settings.-->
<!--Each setting is defined with "settingname", "type" and "value".-->
<!--For details see the CSDK documentation.-->
<Settings>
<!--Set 'Kernel.OcrMgr.DefaultRecognitionModule' setting.-->
<Setting settingname="Kernel.OcrMgr.DefaultRecognitionModule" type="integer" value="RM_OMNIFONT_PLUS3W" />
</Settings>
<!--Definition of the output file.-->
<Output type="string" value="$outputfile1$" />
<!--Definition of the converter used to generate output.-->
<Converter value="Converters.Text.DocX" />
<!--This job item will NOT generate response XML!-->
</JobItem>
<!--clsid: identifies "Statistics" job item type.-->
<!--id: the runtime identifier of this job item instance.-->
<!--dependency: this job item will be started when the job item having id="{fb1e57a3-7c6f-4bca-88b3-b2b979db116e}" finished.-->
<!--"Statistics" job item returns the statistics of the document.-->
<!--For details see Kofax.OmniPageCSDK.IproPlus.Document.GetStatistics.-->
<JobItem clsid="{69490304-CC87-476C-90C3-58B200F6303F}" id="{9dedf984-4ec9-400a-9f29-299deb8123c5}" dependency="{fb1e57a3-7c6f-4bca-88b3-b2b979db116e}">
<!--Definition of the response XML.-->
<OutputXML type="string" value="$xmlfile1$" verbose="true" />
</JobItem>
</OCRJob>
It contains two sequenced job items. The first one is a load/preprocess/locatezones/recognize/export type of job. The second one is the Statistics job, which depends on the first job.
The input comes from $inputfile1$. The recognized text output is saved into $outputfile1$ and the stat numbers are saved into $xmlfile1$.
Your application must change $xxxfilen$ filenames to your actual ones.