The Load Balancer
You can use load balancing if the capacity limit for a single stand-alone Search and Matching Server is reached so that search requests can no longer be responded to in an efficient way. Load balancing makes it possible to use several computers to share computational workload and to distribute the search requests to a set of different Search and Matching Servers. The clients using the Load Balancer access it as if it was a simple Kofax Search and Matching Server with the same interface. The Load Balancer is totally transparent to them. The Load Balancer runs on a classic Microsoft Windows service.
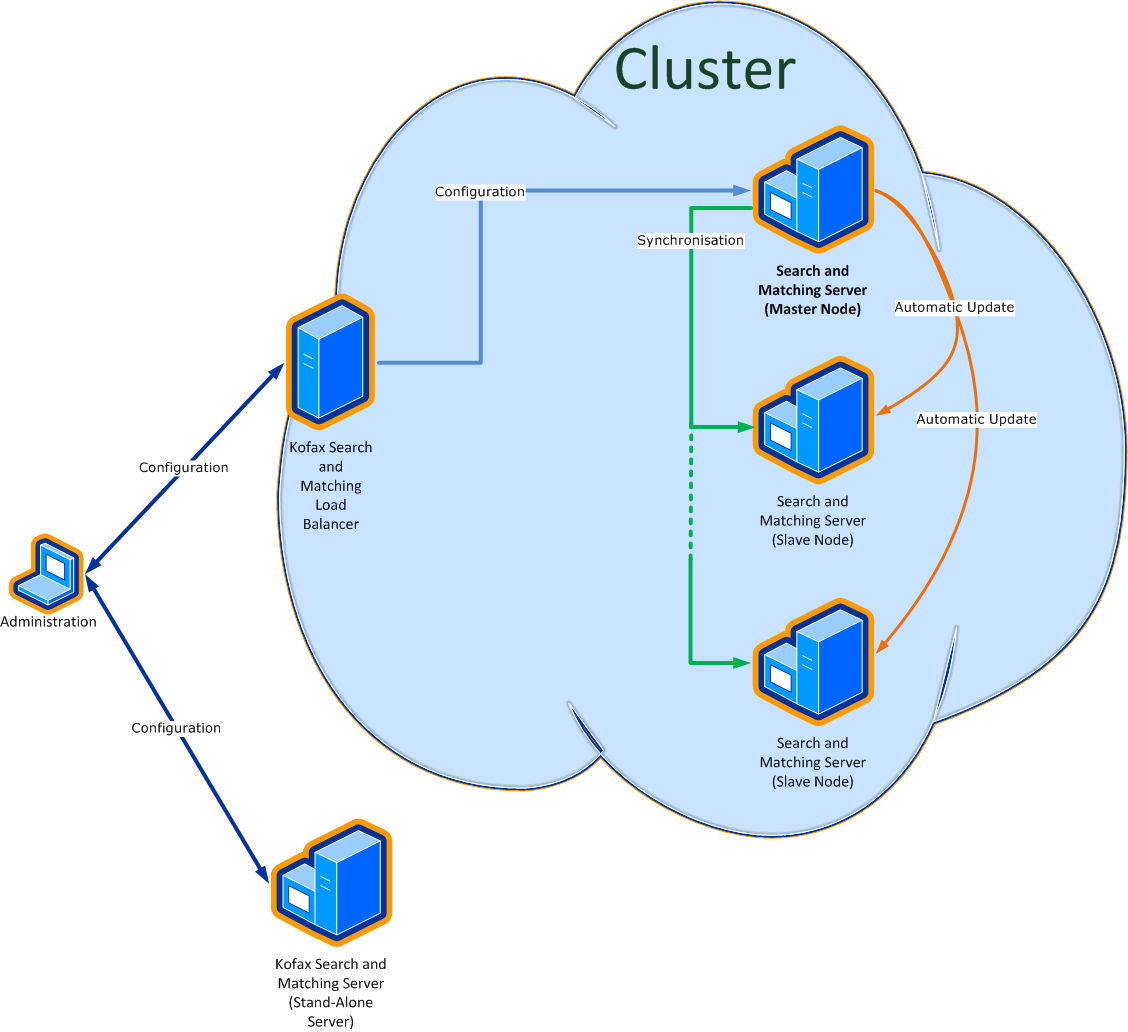
The Load Balancer handles a cluster of several Search and Matching Servers that are defined via the Kofax Search and Matching Server Administration. In the first step you define which Search and Matching Servers form the load balancing cluster and in the second step you set up the databases..
A stand-alone server that is added to a cluster becomes a cluster node and any search requests are then forwarded through the Load Balancer. To minimize the configuration and maintenance effort a cluster always consists of a "master" and one or more "slave" nodes. The databases are defined and configured in the Load Balancer. The selected Load Balancer will push the creation and import of the databases to the master node. When the master is ready, it synchronizes the database automatically to the slave nodes. This way, if you have a relational database, only the master node will access to it, and it will prepare the fuzzy index for the slave nodes. By default, the first server that is added to a cluster is the master node. If you add more servers to the cluster they become slave nodes. All existing databases defined on a server are deleted when a Search and Matching Server is added to the cluster as slave node. The databases on the slave node are synchronized automatically from the master node. If you connect to a slave node via the Administration tool the menu items that are used to configure databases are not available. If needed, for example as a fallback when the Load Balancer is no longer accessible, you can convert a slave node to become a stand-alone server again and configure it or access to it normally. A cluster node that is converted to a stand-alone server is automatically removed from the cluster.
If you delete the master from the cluster you have to select another server (slave) from the list of cluster nodes to become the master. If for any reason no master is defined in the cluster, then databases configuration is not possible, and the automatic update feature from the databases will be skipped. If you add a server that is already member of a different cluster this server is automatically removed from the other cluster. As a kind of fall back you can convert any cluster node to a stand-alone server.
On the client side you configure a remote fuzzy database on a stand-alone Search and Matching Server in the same way as one from a Load Balancer by connecting to either the stand-alone server or the load balancer. For more details see Project Builder Help.
The Load Balancer provides the possibility to handle the search requests from different clients by gathering all search requests from all clients and sending the search requests one after the other to the next available Search and Matching Server in the cluster. This means that each search request is performed by a single Search and Matching Server and not distributed to multiple servers.
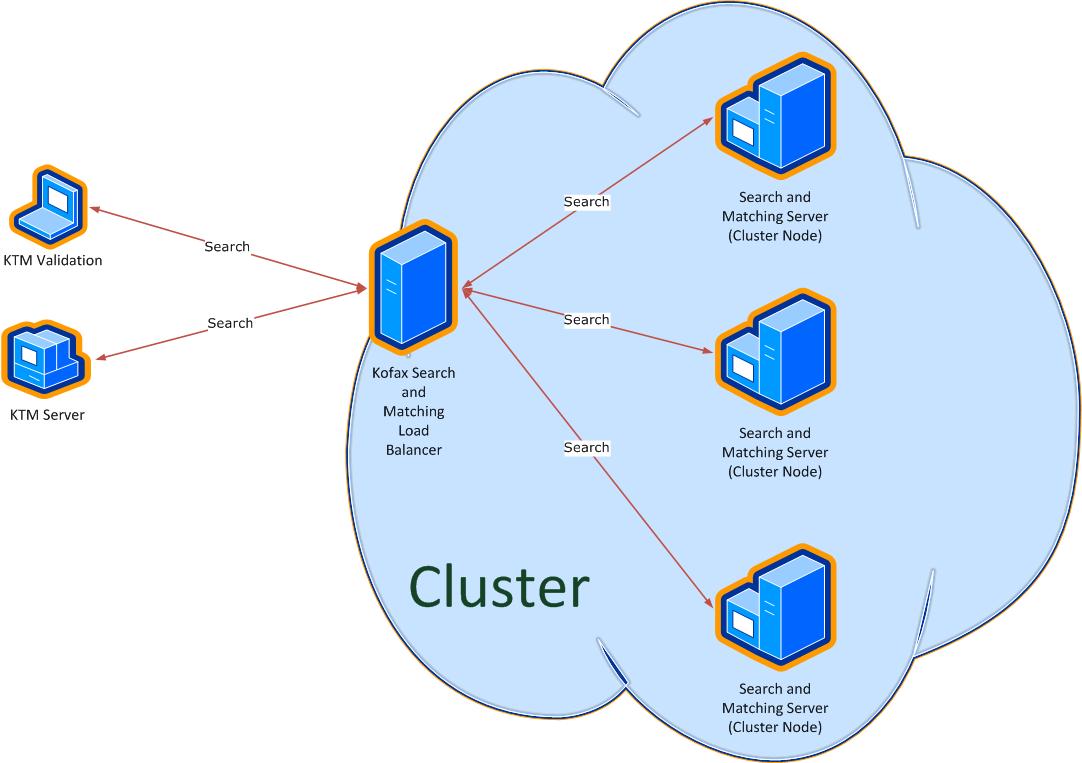
In parallel to handling search requests the Load Balancer synchronizes changes from the master (for example, for a newly-created database or an automatic database update) to all cluster nodes within the cluster. It is fault tolerant in regard to handling search requests or performing synchronization for any cluster node that is temporarily not available. As soon as the node is available again it is reincorporated in the cluster for the search. If needed, the node is updated so that the databases get the latest version..
When you set up load balancing you have to consider that the Load Balancer and all cluster nodes need to share the same settings for the security to ensure a granted access. This means that the services have to run as a user that is member of the "KSMS Administrators" user group configured during installation and this user must have read and write permissions to the data storage directory.
By default, the Load Balancer and Search and Matching Server services are executed for a built-in user account, which is the NETWORK SERVICE user, after the installation.