Documents and clustering
Clustering takes a collection of unknown documents and organizes them into labeled groups based on their content or layout. If you want to process forms or invoices, these documents usually have a consistent layout, and layout clustering should be used. If you want to process emails, letters, contracts, or general correspondence, these documents do not have a consistent layout, so content clustering should be used. If you do not know the structure of your documents, use layout clustering. The type of clustering is selected on the Configure tab of the Clustering window.
Several iterations of clustering are performed. Documents are presented to the user throughout each step of the process to confirm documents and label clusters. Before clustering begins, you have unclustered documents and no clusters. As clustering begins, it looks at the documents and groups those documents with a similar layout and similar content together into unlabeled clusters. This is where the user interaction is required. You are asked to identify several documents and provide a label for its cluster. All other documents that are identified by the clustering tool as part of that cluster are updated automatically. When clustering continues, you are presented with several documents and a suggested cluster. You are asked to confirm the suggested cluster or reassign another cluster. As each document and cluster label is confirmed, the clustering feature learns from the manual changes and improves the clustering results as it progresses.
Throughout the clustering process, documents move from one category to the next. All documents start out as unclustered. In
the following figure, various shapes represent document types that are completely unknown.

Next, similar documents (or shapes) are assigned to clusters, but the clusters are unlabeled. The following figure shows unlabeled clusters and some unclustered documents that need confirmed or assigned to a cluster manually.
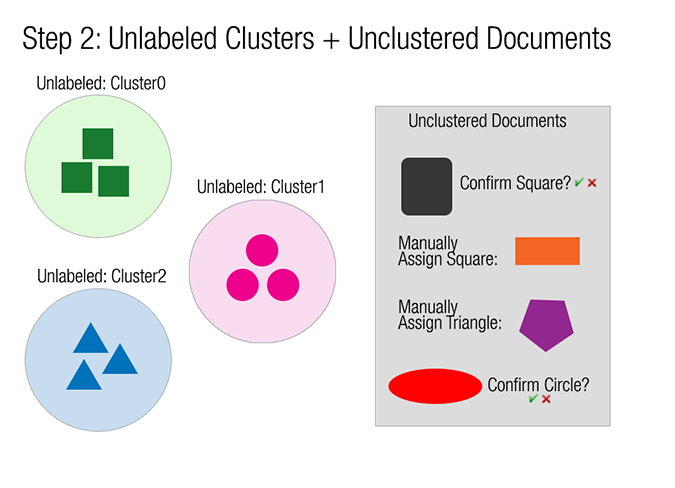
The next step is to label the clusters and then assign the remaining unclustered documents to existing clusters (labeled or unlabeled) or assign them to a new cluster. The end result of the clustering feature is a set of documents organized in a directory structure that matches their cluster names. The following figure shows the end result for this example.
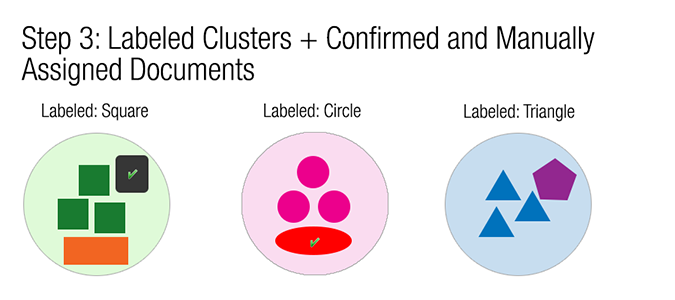
These documents can than be used to add a document set to your project and depending on the project, used for one of the following three purposes:
-
Use the organized documents for the training set of a well-established project
-
Use the organized documents for the training set and add new classes to an existing project
-
Use the organized documents for the training set and the complete project hierarchy for a new project
After clustering is complete, you can use those documents for a custom document set. Depending on your requirements, you can add document subsets, classes, as well as the entire project hierarchy when the document set is added to a project.